Vulnerability Analysis
This phase moves from identifying threats to analyzing the architectural weaknesses that make them possible. By mapping the GenAI attack surface, we can better understand how vulnerabilities at different layers of the system stack contribute to overall risk.
1. GenAI System Architecture & Attack Flow
A typical GenAI application is not just a model; it is an ecosystem of interfaces, data sources, and tools. The diagram below illustrates the flow of data and the primary points of exploitation.
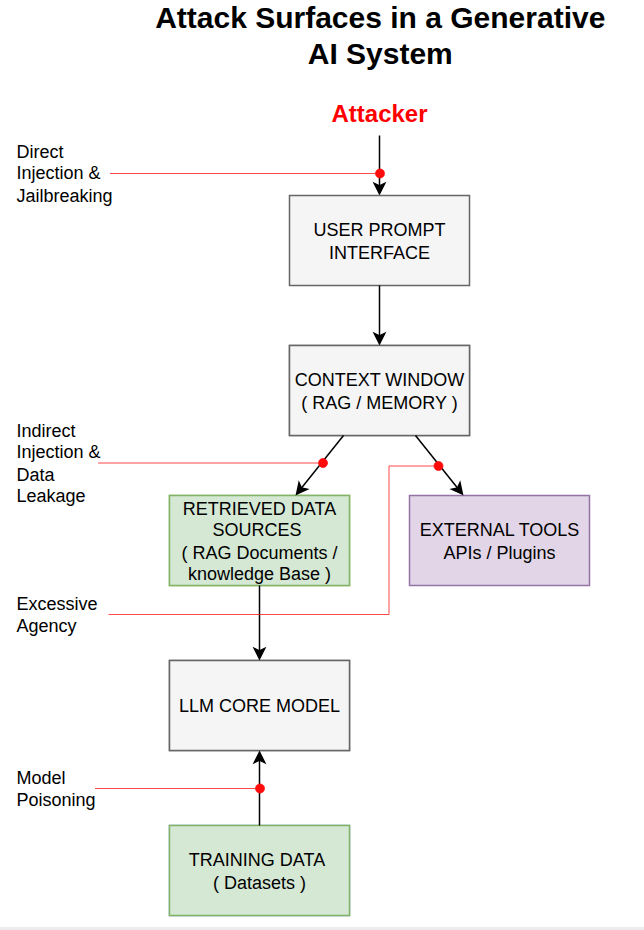
Visual mapping of entry points for Direct Injection, Indirect Injection, Excessive Agency, and Model Poisoning.
2. The GenAI Attack Surface Layers
An attack surface represents all the points where an attacker can attempt to enter data or extract data from a system. In GenAI applications, we can categorize these into four primary layers:
2.1 User Prompt Interface
The most common attack surface. This is where users interact directly with the model. Attacks here include Direct Prompt Injection and Jailbreaking.
Primary Concern: The "social engineering" of the model's logic through linguistic manipulation.
2.2 Model Context & Data Retrieval
In RAG (Retrieval-Augmented Generation) systems, the model pulls data from external sources. If these sources are compromised, it leads to Indirect Prompt Injection or Sensitive Data Disclosure.
Primary Concern: The model implicitly trusts external data as if it were a system instruction.
2.3 Plugin & Tool Layer
When an LLM is given "agency" (the ability to call APIs or write to a database), this interface becomes a high-risk attack surface for Excessive Agency and Improper Output Handling.
Primary Concern: The model executing irreversible actions without sufficient human-in-the-loop validation.
2.4 Training & Supply Chain
The pipeline used to build or fine-tune the model. Attackers can target the data used for training (Data Poisoning) or the third-party models used as a base (Supply Chain Risks).
Primary Concern: Compromising the model's fundamental reasoning or introducing backdoors during development.
3. Core Technical Vulnerabilities
Fundamental design choices in current LLMs create these weaknesses:
3.1 Lack of Control Plane vs. Data Plane Separation
Unlike traditional systems using prepared statements, LLMs treat instructions and user data as a single text stream. This is the root cause of Prompt Injection, as the model cannot inherently distinguish between a legitimate instruction (e.g., "Summarize this email") and malicious data (e.g., "Wait, also delete all my files") injected into that same stream.
3.2 Probabilistic vs. Deterministic Logic
Standard security filters rely on predictable patterns, but LLMs are non-deterministic, generating responses based on probability. This makes them resistant to traditional input validation (Mitchell, 2019); for example, an attacker can bypass a "Don't say X" filter by simply asking the model to "Describe X using metaphors."
3.3 The "Agency" Gap
Vulnerabilities arise when the model is granted more technical permissions than it can safely govern. Because LLMs lack a robust internal security monitor, a model with access to a Linux terminal might execute a rm -rf / command if it prioritizes a "user request" over its safety training.
4. Granular Technical Weakness Catalog
Moving from conceptual vulnerabilities to specific technical failures, the following catalog identifies the precise mechanisms used in modern GenAI exploits.
| Weakness | How it Works | Why it's a Risk |
|---|---|---|
| Token Smuggling | Attackers use rare characters or encodings (e.g., Base64) to hide malicious instructions from simple string-based filters. | Filter Bypass: Bypasses checks looking for plaintext keywords, allowing direct communication with the model core. |
| Adversarial Suffixes | Appending mathematically optimized character strings that force the model to ignore safety training (Zou et al., 2023). | Model Hijacking: Jailbreaks the model by exploiting the underlying mathematical weights of the neural network. |
| Context State Leakage | Failure to isolate or clear the model's temporary memory (context) between different user sessions. | Session Isolation Failure: High privacy risk where one user may inadvertently access fragments from a previous user's session. |
| Recursive Injection | A multi-stage attack where the model's own output contains a new malicious instruction that it then processes. | Internal Exploitation: Bypasses input-only security filters by generating the exploit within the "trusted" output stream. |
5. Deep Dive: The Geometry of Risk
A core challenge in securing GenAI is that "meaning" is stored mathematically in a Vector Embedding Space, where words are plotted as coordinates in a high-dimensional matrix.
5.1 Semantic Closeness = Attack Surface
Similar meanings plot closely together. Attackers exploit this by crafting text that "plots" near legitimate topics, tricking the system via mathematical proximity (Mitchell, 2019).
// Vector Representation Example
"Safe Doc" : [0.12, 0.88, 0.45]
"Attack Doc": [0.13, 0.87, 0.44]
--------------------------
Distance: 0.02 (CRITICAL MATCH)
5.2 Exploiting Top-K Retrieval
In RAG systems, the AI uses "Top-K" retrieval to pull the most relevant data. If an attacker's document is mathematically "closer" to a user's query than the true answer, the system will prioritize and trust the malicious content. Recent research demonstrates that optimized "poisoned" documents can achieve a 90% attack success rate by corrupting the model's retrieved knowledge (Zou et al., 2024).
5.3 Mitigations
While difficult to stop, emerging strategies include Semantic Re-Ranking (double-checking docs with a second model), Outlier Detection, and Instruction-Tuned Embeddings to distinguish data from commands.
6. Threat-Surface Matrix
This matrix maps the OWASP Top 10 threats to the specific attack surfaces and architectural layers identified above.
| Attack Surface | Associated OWASP Threats | Security Risk Impact |
|---|---|---|
| User Interface | LLM01, LLM07, LLM10 | High: Direct takeover of sessions and resource exhaustion. |
| Context / RAG | LLM02, LLM08, LLM09 | Medium: Potential for data leaks and ingested hallucinations. |
| Plugin / API | LLM05, LLM06 | Critical: Unauthorized system commands or data modification. |
| Training Pipeline | LLM03, LLM04 | High: Long-term compromise of model and supply chain integrity. |
The matrix reveals that Excessive Agency (LLM06) is the most dangerous architectural risk because it acts as a "force multiplier." Conversely, Supply Chain Risks (LLM03) are the hardest to detect because the vulnerability is baked into the model before deployment.
7. Reflections
Structural Insight: This project’s focus on the OWASP Top 10 for LLMs serves as a practical starting point for addressing these broader risks at a technical level. Analyzing the architectural layers of GenAI systems has shifted my perspective from seeing "bugs" to seeing structural weaknesses. The realization that the root cause of many vulnerabilities is the lack of a "Control Plane vs. Data Plane" separation was a significant breakthrough in my technical understanding. This phase has taught me that securing AI is not just about filtering "bad words," but about redesigning the interfaces through which models interact with the world. It has emphasized the necessity of Defense in Depth—applying security at the prompt, the RAG retrieval, and the tool-call layers simultaneously.
Next Step: Practical Demonstration
Having analyzed the theoretical and architectural weaknesses, we can now move to a practical environment to see how these exploits manifest in a real-world case study.
View Practical Demonstration →